This is part 2 of a series of posts I’m doing for a friend who’s a JavaScript developer that, according to him, knows next to nothing about Postgres. You can read part 1 right here.
I write a lot about Postgres, but I don’t think I’ve written enough about how to get started from the absolute beginning, so that’s what we’re doing here.
In this post, I’m continuing with his questions to me - but this time it has less to do with the database side of things and more to do with Node and how you can use Postgres for fun and profit. Let’s roll.
How should I structure my code?
This question has more to do with your preferences or what your company/boss have set up. I can show you how I do things, but your situation is probably a lot different.
OK, enough prevaricating. Here’s what I’ve done in the past with super simple projects that where I’m just musing around.
Give PG It’s Own Module
I like putting all my code inside of a lib directory, and then inside there I’ll create a a pg directory with specific connection things etc for Postgres. It looks like this:
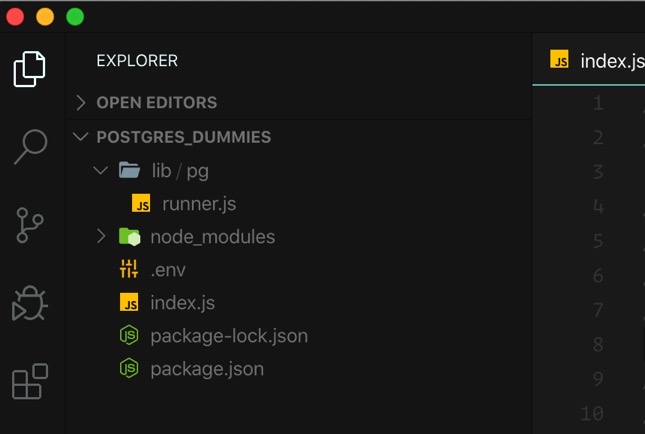
You’ll also notice I have a .env file, which is something that goes into every single project of mine. It’s a file that holds environmental variables that I’ll be using in my project. In this case, I do not want my connection string hardcoded anywhere - so I pop it into a .env file where it’s loaded automatically by my shell (zshell and, for those interested, I use the dotenv plugin with Oh-My-Zsh).
There’s a single file inside of the lib/pg directory called runner.js, and it has one job: run the raw SQL queries using pg-promise:
const pgp = require('pg-promise')({});
const db = pgp(process.env.DATABASE_URL);
exports.query = async function(sql, args){
const res = await db.any(sql, args);
return res;
}
exports.one = async function(sql, args){
const res = await db.oneOrNone(sql, args);
return res;
}
exports.execute = async function(sql, args){
const res = await db.none(sql, args);
return res;
}
exports.close = async function(){
await db.$pool.end();
return true;
}
I usually have 3 flavors of query runners:
- One that will return 0 to n records
- One that will return a single record
- One that executes a “passthrough” query that doesn’t return a result
I also like to have one that closes the connections down. Normally you wouldn’t call this in your code because the driver (which is pg-promise in this case) manages this for you and you want to be sure you draw on its pool of connections - don’t spin your own. That said, sometimes you might want to run a script or two, maybe some integration tests might hit the DB - either way a graceful shutdown is nice to have.
We can use this code in the rest of our app:
const pg = require("./lib/pg/runner");
pg.query("select * from master_plan limit 10")
.then(console.log)
.catch(console.error)
.finally(pg.close)
Neat! It works well but yes, we’ll end up with SQL all over our code so let’s fix that.
A Little Bit of Abstraction
The nice thing about Node is that your modules can be single files, or you can expand them to be quite complex - without breaking the code that depends on them. I don’t want my app code to think about the SQL that needs to be written - I’d rather just offer a method that gives the data I want. In that case, I’ll create an index.js file for my pg module, which returns a single method for my query called masterPlan:
const runner = require("./runner");
exports.masterPlan = function(limit=10){
return runner.query(`select * from master_plan limit ${limit}`)
}
exports.shutDown = function(){
runner.close();
}
The runner here is the same runner that I used before, this time it’s in the same directory as the calling code. I’ve exposed two methods on the index as that’s all I need for right now. This is kind of like a Repository Pattern, which comes with a few warnings attached.
People have been arguing about data access for decades. What patterns to use, how those patterns fit into the larger app you’re building, etc, etc, etc. It’s really annoying.
Applications always start small and then grow. That’s where the issues come in. The Repository Pattern looks nice and seems wonderful until you find yourself writing Orders.getByCustomer and Customer.getOrders, wondering if this is really what you wanted to do with your life.
This is a rabbit hole I don’t want to go down further so, I’ll kindly suggest that if you have a simple app with 10-20 total queries, this level of control and simplicity of approach might work really well. If your app will grow (which I’m sure it will whether you think so or not), it’s probably a good idea to use some kind of library or relational mapper (ORM), which I’ll get to in just a minute.
How do I put JSON in it?
One of the fun things about Node is that you can work with JSON everywhere. It’s fun, I think, to not worry about data types, migrations, and relational theory when you’re trying to get your app off the ground.
The neat thing about Postgres is that it supports this and it’s blazing fast. Let’s see how you can set this up with Postgres.
Saving a JSONB Document
Postgres has native support for binary JSON using a datatype called “JSONB”. It behaves just like JSON but you can’t have duplicate keys. It’s also super fast because you can index it in a variety of ways.
Since we’re going to store our data in a JSONB field, we can create a “meta” table in Postgres that will hold that data. All we need is a primary key, a timestamp and the field to hold the JSON:
create table my_document_table(
id serial primary key,
doc jsonb not null,
created_at timestamp not null default now()
);
We can now save data to it using a query like this:
insert into my_document_table(doc)
values('{"name":"Burke Holland"}');
And yuck. Why would anyone want to do something like this? Writing delimited JSON by hand is gross, let’s be good programmers and wrap this in a function:
const runner = require("./runner");
//in pg/index.js
exports.saveDocument = async function(doc){
const sql = "insert into my_document_table (doc) values ($1)";
const res = await runner.one(sql, [doc]);
return res;
}
This works really well, primarily because our Node driver (pg-promise) understands how to translate JavaScript objects into something Postgres can deal with. We just pass that in as an argument.
But we can do better than this, don’t you think?
Sprinkling Some Magical Abstraction
One of the cool things about using a NoSQL system is that you can create a document table on the fly. We can do that easily with Postgres but we just need to tweak our saveDocument function a bit. In fact we need to tweak a lot of things.
Let’s be good programmers and create a brand new file called jsonb.js inside our pg directory, right next to our runner.js file. The first thing we’ll do is to create a way to save any document and, if we get an error about a table not existing, we’ll create it on the fly!
exports.save = async function(tableName, doc){
const sql = `insert into ${tableName} (doc) values ($1) returning *`;
try{
const newDoc = await runner.one(sql, [doc]);
doc.id = newDoc.id;
return doc;
}catch(err){
if(err.message.indexOf("does not exist") > 0){
//create the table on the fly
await this.createDocTable(tableName);
return this.save(tableName,doc);
}
}
}
exports.createDocTable = async function(tableName){
await runner.query(`
create table ${tableName}(
id serial primary key,
doc jsonb not null,
created_at timestamp not null default now()
)`);
await runner.query(`
create index idx_json_${tableName}
on ${tableName}
USING GIN (doc jsonb_path_ops)
`);
}
We have two groovy functions that we can use to save a document to Postgres with the sweetness of a typical NoSQL, friction-free experience. A few things to note about this code:
- We’re catching a specific error when a table doesn’t exist in the database. There’s probably a better way to do that, so feel free to play around. If there’s an error, we’re creating the table and then calling the
savefunction one more time. - The
createDocTablefunction also pops an index on the table which usesjsonb_path_ops. That argument tells Postgres to index every key in the document. This might not be what you want, but indexing is a good thing for smaller documents. - We’re using a fun clause at the end of our
insertSQL statement, specificallyreturning *which will return the entire, newly-created record, which we can then pass on to our calling code.
Let’s see if it works!
//index.js of our project
docs.save("customers", {name: "Mavis", email: "[email protected]"})
.then(console.log)
.catch(console.err)
.finally(pg.shutDown);
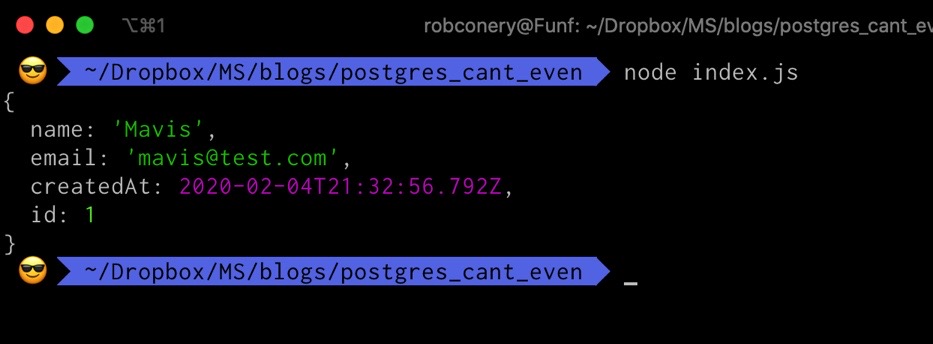
Well look at that would ya! It works a treat.
But what about updates and deletes? Deleting a document is a simple SQL statement:
exports.delete = async function(id) {
const sql = `delete from ${tableName} where id=$1`;
await runner.execute(sql, [id]);
return true;
};
You can decide what to return from here if you want, I’m just returning true. Updating is a different matter, however.
Updating an existing JSONB document
One of the problems with JSONB and Postgres in the past (< 9.5) was that in order to update a document you had to wholesale update it - a “partial” update wasn’t possible. With Postgres 9.5 that changed with the jsonb_set method, which requires a key and a JSONB element.
So, if we wanted to change Mavis’s email address, we could use this SQL statement:
update customers
set doc = jsonb_set(doc, '{"email"}', '"[email protected]"')
where id = 1;
That syntax is weird, don’t you think? I do. It’s just not very intuitive as you need to pass an “array literal” to define the key and a string value as the new value.
To me it’s simpler to just concatenate a new value and do a wholesale save. It’s nice to know that a partial update is possible if you need it, but overall I’ve never had a problem just running a complete update like this:
exports.modify = async function(tableName, id = 0, update = {}) {
if (!tableName) return;
const sql = `update customers SET
doc = (doc || $1)
where id = $2 returning *; `;
const res = await runner.one(sql, [update, id]);
return res;
};
The || operator that you see there is the JSONB concatenation operator which will update an existing key in a document or add one if it’s not there. Give it a shot! See if it updates as you expect.
Querying a JSONB document by ID
This is the nice thing about using a relational system like Postgres: querying by id is just a simple SQL statement. Let’s create a new function for our jsonb module called get, which will return a document by ID:
exports.get = async function(tableName, id=0){
const sql = `select * from ${tableName} where id=$1`;
const record = await runner.one(sql, [id]);
const doc = record.doc;
doc.id = record.id;
return doc;
}
Simple enough! You’ll notice that i’m adding the id of the row in Postgres to the document itself. I could drop that into the document itself, if I wanted, but it’s simple enough to tack it on as you see. In fact, I think I’d like to ensure the created_at timestamp is on too, so let’s formalize this with some transformations:
const transformRecord = function(record){
if(record){
const doc = record.doc;
doc.createdAt = record.created_at;
doc.id = record.id;
return doc;
}else{
return null;
}
}
const transformSet = function(res){
if(res === null || res === []) return res;
const out = [];
for(let record of res){
const doc = transformRecord(record);
out.push(doc)
}
return out;
}
This will take the raw record from Postgres and turn it into something a bit more usable.
Querying a document using criteria
We can pull data out of our database using an id, but we need another way to query if we’re going to use this properly.
You can query documents in Postgres using a special operator: @>. There are other operators, but this is the one we’ll need for 1) querying specific keys and 2) making sure we use an index. There are all kinds of operators and functions for JSONB within Postgres and you can read more about them here.
To query a document for a given key, you can do something like this:
select * from customers
where doc @> '{"name":"Burke Holland"}';
This query is simply for documents where the key/value {name:"Burke Holland"} exists. That critieria is simply JSON, which means we can pass that right through to our driver… and behold:
exports.find = async function(tableName, criteria){
const sql = `select * from ${tableName} where doc @> $1`;
const record = await runner.query(sql, [criteria]);
return transformSet(record);
}
Let’s run this and see if it works:
docs.find("customers", {email: "[email protected]"})
.then(console.log)
.catch(console.err)
.finally(pg.shutDown);
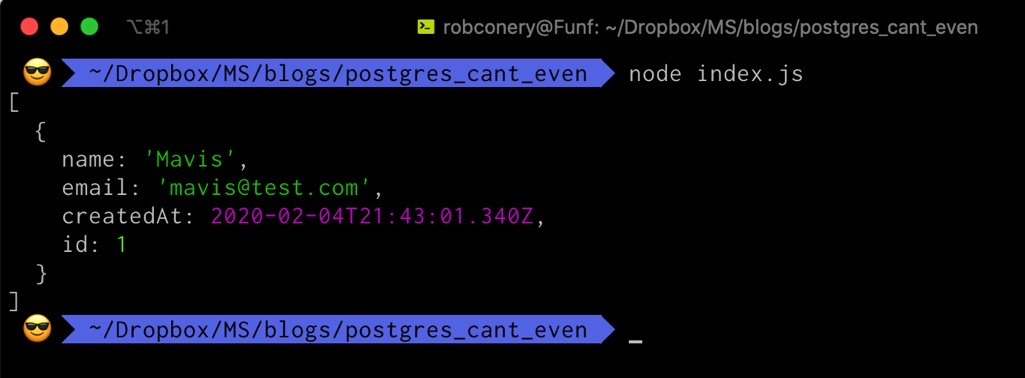
Hey that’s pretty swell! You don’t need to use dedicated JSON operators to query a JSONB document in Postgres. If you’re comfortable with SQL, you can just execute a regular old query and it works just fine:
select * from customers
where (doc ->> 'name') ilike 'Mav%'
Here, we’re pulling the name key from the document using the JSON text selector (->>), and then doing a fuzzy comparison using ilike (case-insensitive comparison). This works pretty well but it can’t use the index we setup and that might make your DBA mad.
That doesn’t mean you can’t index it - you can!
create index idx_customer_name
on customers((doc ->> 'name'));
Works just like any other index!
Play around, have some fun…
I made a gist out of all of this if you want to goof around. There are things to add, like updates/partial updates, and I encourage you to play and have a good time.
If you’re wondering, however, if someone, somewhere, might have baked this stuff into a toolset… indeed! They did…
Are there any ORM-like tools in it? What do you recommend?
So here’s the thing: if you’re coming to this post from a Java/C#/Enterprise-y background, the “ORM” tools in the Node world are going to look … well a bit different. I don’t know the reason why and I could pontificate about Node in the enterprise or how Node’s moduling system pushes the idea of isolation… but… let’s just skip all of that OK?
The bottom line is this: you can do data access with Node, but if you’re looking for an industrial strength thing to rival Entity Framework you might be dissapointed. With that said - let’s have a look…
My favorite: MassiveJS
I am 100% completely biased when it comes to MassiveJS because… well I created it along with my friend Karl Seguin back in 2011 or so. The idea was to build a simple data access tool that would help you avoid writing too much SQL. It morphed into something much, much fun.
With version 2 I devoted Massive to Postgres completely and was joined by the current owner of the project, Dian Fay. I can’t say enough good things about Dian - she’s amazing at every level and has turned this little project into something quite rad. Devoting Massive 100% to Postgres freed us up to do all kinds of cool things - including one of the things I love most: document storage.
The code you read above was inspired by the work we did with JSONB and Massive. You can have a fully-functioning document storage solution that kicks MongoDB in the face in terms of speed, fuzzy searches, full-text indexing, ACID guarantees and a whole lot more. Massive gives you the same, simple document API and frictionless experience you get with Mongo with a much better database engine underneath.
To work with Massive, you create an instance of your database which reads in all of your tables and then allows you to query them as if they were properties (the examples below are taken from the documentation):
const massive = require('massive');
const db = await massive({
host: 'localhost',
port: 5432,
database: 'appdb',
user: 'appuser',
password: 'apppwd',
ssl: false,
poolSize: 10
});
//save will update or insert based on the presence of an
//ID field
let test = await db.tests.save({
version: 1,
name: 'homepage'
});
// retrieve active tests 21-30
const tests = await db.tests.find({is_active: true}, {
offset: 20,
limit: 10
});
Working with documents looks much the same as the relational stuff above, but it’s stored as JSON:
const report = await db.saveDoc('reports', {
title: 'Week 12 Throughput',
lines: [{
name: '1 East',
numbers: [5, 4, 6, 6, 4]
}, {
name: '2 East',
numbers: [4, 4, 4, 3, 7]
}]
});
Finally, the thing I love most about the project is what Dian has done with the documentation (linked above). She goes into detail about every aspect of the tool - even how to use it with popular web frameworks.
Sequelize
One of the more popular data access tools - let’s call it a full on ORM - is Sequelize. This tool is a traditional ORM in every sense in that it allows you create classes and save them to multiple different storage engines, including Postgres, MySQL/MariaDB SQLite and SQL Server. It’s kind of not an ORM though because there is no mapping (the “M”) that you can do aside from a direct 1:1, ActiveRecord style. For that, you can project what you need using map and I’ll just leave that discussion right there.
If you’ve used ActiveRecord (Rails or the pattern itself) before then you’ll probably feel really comfortable with Sequelize. I used it once on a project and found its use straightforward and simple to understand. Getting started was also straightforward, as with any ORM, and the only question is how well an ActiveRecord pattern fits your project’s needs both now and into the future. That’s for you to decide and this is where I hit the architectural eject button again (even though I did once before which didn’t seem to work).
Let’s have a look at some of the examples that come from the documentation.
Connecting is straightforward:
const Sequelize = require('sequelize');
const sequelize = new Sequelize('postgres://user:[email protected]:5432/dbname');
Declaring a “model” in Sequelize is matter of creating a class and extending from Sequelize.Model or using a built-in definition method. I prefer the latter:
const User = sequelize.define('user', {
// attributes
firstName: {
type: Sequelize.STRING,
allowNull: false
},
lastName: {
type: Sequelize.STRING
// allowNull defaults to true
}
}, {
// options
});
Sequelize is capable of using this model definition and generating, or “sychronizing” your database just like Django’s ORM does. That’s really helpful in the early days of your project or if you just hate migrations as much as I do.
Sequelize is an outstanding data tool that allows you to work with your database in a seamless way. It has powerful queries and can handle some pretty intense filtering:
Project.findOne({
where: {
name: 'a project',
[Op.not]: [
{ id: [1,2,3] },
{ array: { [Op.contains]: [3,4,5] } }
]
}
});
If you’ve worked with Rails and ActiveRecord Sequelize should feel familiar when it comes to associations, hooks and scopes:
class User extends Model { }
User.init({
name: Sequelize.STRING,
email: Sequelize.STRING
},
{
hooks: {
beforeValidate: (user, options) => {
user.mood = 'happy';
},
afterValidate: (user, options) => {
user.username = 'Toni';
}
},
sequelize,
modelName: 'user'
});
class Project extends Model { }
Project.init({name: Sequelize.STRING}, {
scopes: {
deleted: {
where: {
deleted: true
}
},
sequelize,
modelName: 'project'
}
});
User.hasOne(Project);
And there you have it. The documentation for Sequelize is very complete as well, with examples and SQL translations so you know what query will be produced for every call.
But what about…?
There are so many tools out there that can help you with Node and data access and I’m sure I’ve left a few off, so feel free to add your favorite in the comments. Please be sure it works with Postgres AND please be sure to indicate why you like it!
Postgres is neat and all but how do I deploy my database?
Great question! That will have to be a topic for Part 3, unfortunately as this post is quite long and I have a lot of ideas. We’ll go simple and low fidelity with a simple docker container push, and then look at some of the hosted, industrial strength solutions out there - including Azure’s Managed Postgres offering!